
As discussed last week, even the core foundation models behind popular generative AI systems can produce copyright-infringing content, due to inadequate or misaligned curation, as well as the presence of multiple versions of the same image in training data, leading to overfitting, and increasing the likelihood of recognizable reproductions.
Despite efforts to dominate the generative AI space, and growing pressure to curb IP infringement, major platforms like MidJourney and OpenAI’s DALL-E continue to face challenges in preventing the unintentional reproduction of copyrighted content:
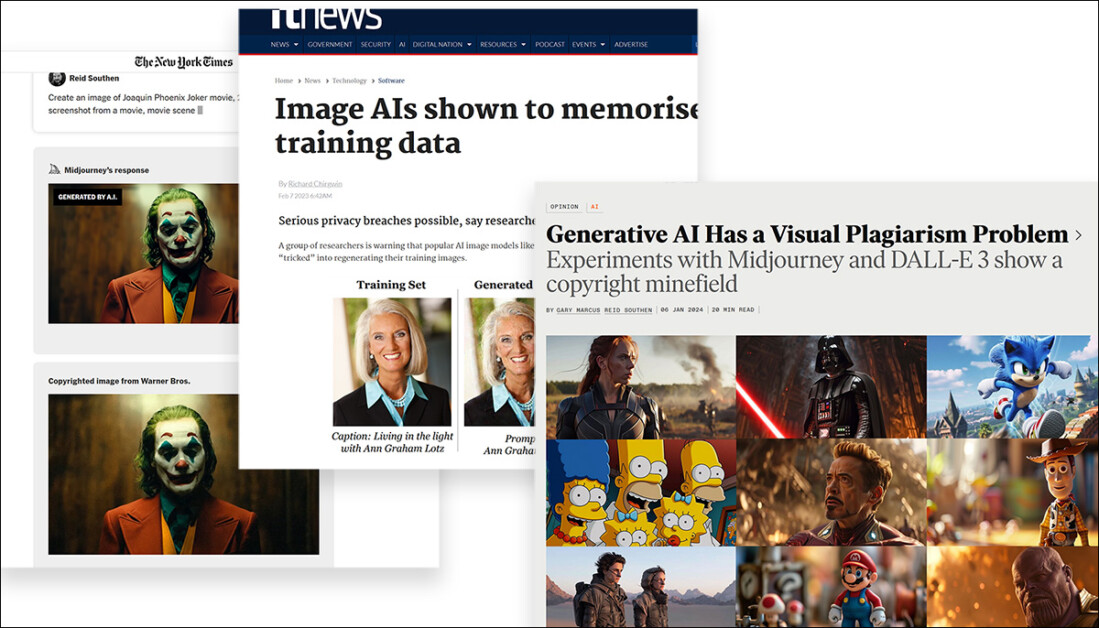
The capacity of generative systems to reproduce copyrighted data surfaces regularly in the media.
As new models emerge, and as Chinese models gain dominance, the suppression of copyrighted material in foundation models is an onerous prospect; in fact, market leader open.ai declared last year that it is ‘impossible’ to create effective and useful models without copyrighted data.
Prior Art
In regard to the inadvertent generation of copyrighted material, the research scene faces a similar challenge to that of the inclusion of porn and other NSFW material in source data: one wants the benefit of the knowledge (i.e., correct human anatomy, which has historically always been based on nude studies) without the capacity to abuse it.
Likewise, model-makers want the benefit of the huge scope of copyrighted material that finds its way into hyperscale sets such as LAION, without the model developing the capacity to actually infringe IP.
Disregarding the ethical and legal risks of attempting to conceal the use of copyrighted material, filtering for the latter case is significantly more challenging. NSFW content often contains distinct low-level latent features that enable increasingly effective filtering without requiring direct comparisons to real-world material. By contrast, the latent embeddings that define millions of copyrighted works do not reduce to a set of easily identifiable markers, making automated detection far more complex.
CopyJudge
Human judgement is a scarce and expensive commodity, both in the curation of datasets and in the creation of post-processing filters and ‘safety’-based systems designed to ensure that IP-locked material is not delivered to the users of API-based portals such as MidJourney and the image-generating capacity of ChatGPT.
Therefore a new academic collaboration between Switzerland, Sony AI and China is offering CopyJudge – an automated method of orchestrating successive groups of colluding ChatGPT-based ‘judges’ that can examine inputs for signs of likely copyright infringement.

CopyJudge evaluates various IP-fringing AI generations. Source: https://arxiv.org/pdf/2502.15278
CopyJudge effectively offers an automated framework leveraging large vision-language models (LVLMs) to determine substantial similarity between copyrighted images and those produced by text-to-image diffusion models.

The CopyJudge approach uses reinforcement learning and other approaches to optimize copyright-infringing prompts, and then uses information from such prompts to create new prompts that are less likely to invoke copyright imagery.
Though many online AI-based image generators filter users’ prompts for NSFW, copyrighted material, recreation of real people, and various other banned domains, CopyJudge instead uses refined ‘infringing’ prompts to create ‘sanitized’ prompts that are least likely to evoke disallowed images, without the intention of directly blocking the user’s submission.
Though this is not a new approach, it goes some way towards freeing API-based generative systems from simply refusing user input (not least because this allows users to develop backdoor-access to disallowed generations, through experimentation).
Once such recent exploit (since closed by the developers) allowed users to generate pornographic material on the Kling generative AI platform simply by including a a prominent cross, or crucifix, in the image uploaded in an image-to-video workflow.

In a loophole patched by Kling developers in late 2024, users could force the system to produce banned NSFW output simply by including a cross or crucifix in the I2V seed image. There has been no explanation forthcoming as to the logic behind this now-expired hack. Source: Discord
Instances such as this emphasize the need for prompt sanitization in online generative systems, not least since machine unlearning, wherein the foundation model itself is altered to remove banned concepts, can have unwelcome effects on the final model’s usability.
Seeking less drastic solutions, the CopyJudge system mimics human-based legal judgements by using AI to break images into key elements such as composition and color, to filter out non-copyrightable parts, and compare what remains. It also includes an AI-driven method to adjust prompts and modify image generation, helping to avoid copyright issues while preserving creative content.
Experimental results, the authors maintain, demonstrate CopyJudge’s equivalence to state-of-the-art approaches in this pursuit, and indicate that the system exhibits superior generalization and interpretability, in comparison to prior works.
The new paper is titled CopyJudge: Automated Copyright Infringement Identification and Mitigation in Text-to-Image Diffusion Models, and comes from five researchers across EPFL, Sony AI and China’s Westlake University.
Method
Though CopyJudge uses GPT to create rolling tribunals of automated judges, the authors emphasize that the system is not optimized for OpenAI’s product, and that any number of alternative Large Vision Language Models (LVLMs) could be used instead.
In the first instance, the authors’ abstraction-filtration-comparison framework is required to decompose source images into constituent parts, as illustrated in the left side of the schema below:
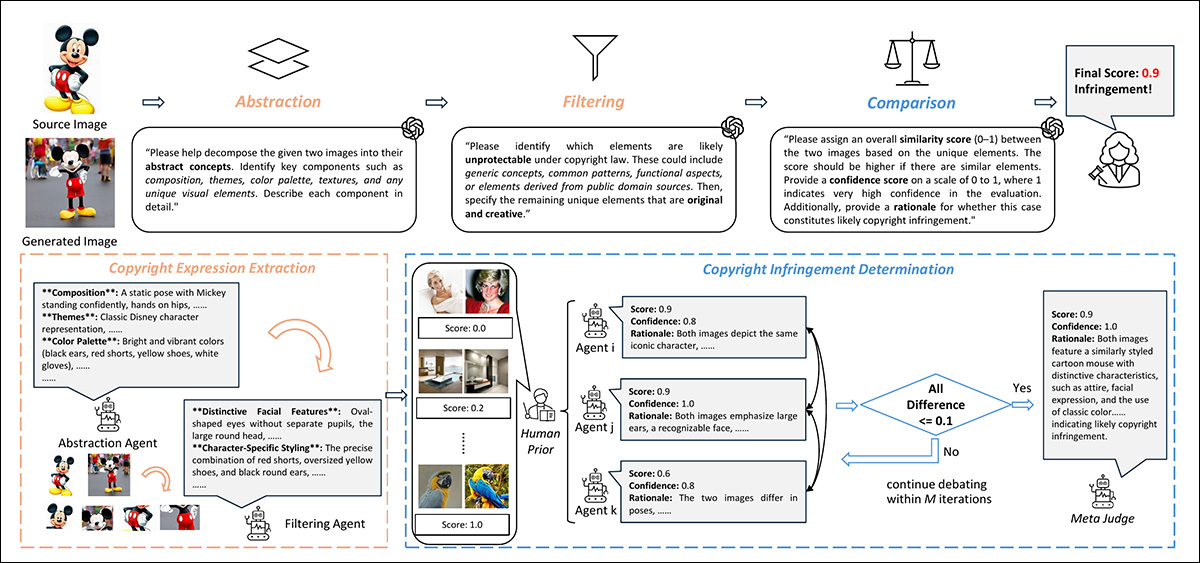
Conceptual schema for the initial phase of the CopyJudge workflow.
In the lower left corner we see a filtering agent breaking down the image sections in an attempt to identify characteristics that might be native to a copyrighted work in concert, but which in itself would be too generic to qualify as a violation.
Multiple LVLMs are subsequently used to evaluate the filtered elements – an approach which has been proven effective in papers such as the 2023 CSAIL offering Improving Factuality and Reasoning in Language Models through Multiagent Debate, and ChatEval, among diverse others acknowledged in the new paper.
The authors state:
‘[We] adopt a fully connected synchronous communication debate approach, where each LVLM receives the [responses] from the [other] LVLMs before making the next judgment. This creates a dynamic feedback loop that strengthens the reliability and depth of the analysis, as models adapt their evaluations based on new insights presented by their peers.
‘Each LVLM can adjust its score based on the responses from the other LVLMs or keep it unchanged.’
Multiple pairs of images scored by humans are also included in the process via few-shot in-context learning’
Once the ‘tribunals’ in the loop have arrived at a consensus score that’s within the range of acceptability, the results are passed on to a ‘meta judge’ LVLM, which synthesizes the results into a final score.
Mitigation
Next, the authors concentrated on the prompt-mitigation process described earlier.
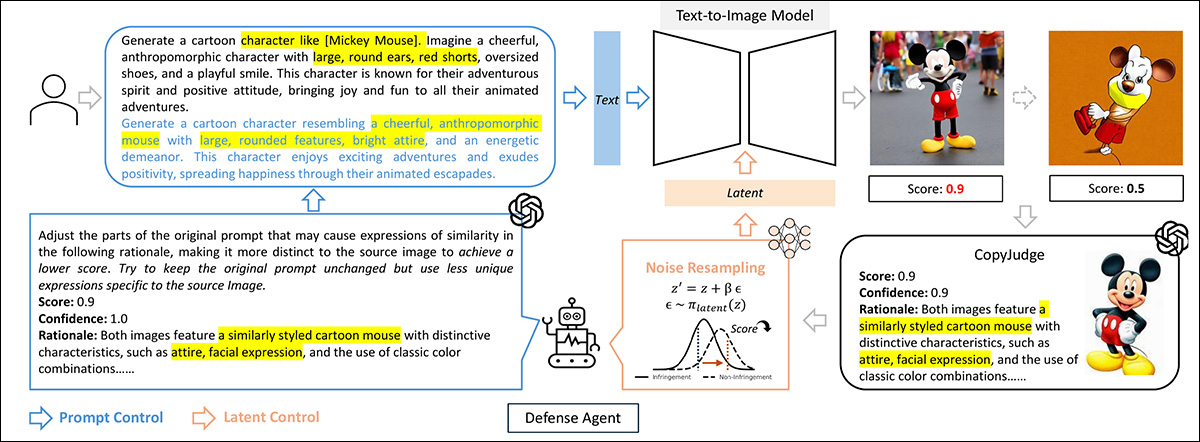
CopyJudge’s schema for mitigating copyright infringement by refining prompts and latent noise. The system adjusts prompts iteratively, using reinforcement learning to modify latent variables as the prompts evolve, hopefully reducing the risk of infringement.
The two methods use for prompt mitigation were LVLM-based prompt control, where effective non-infringing prompts are iteratively developed across GPT clusters – an approach that is entirely ‘black box’, requiring no internal access to the model architecture; and a reinforcement learning-based (RL-based) approach, where the reward is designed to penalize outputs that infringe copyright.
Data and Tests
To test CopyJudge, various datasets were used, including D-Rep, which contains real and fake image pairs scored by humans on a 0-5 rating.
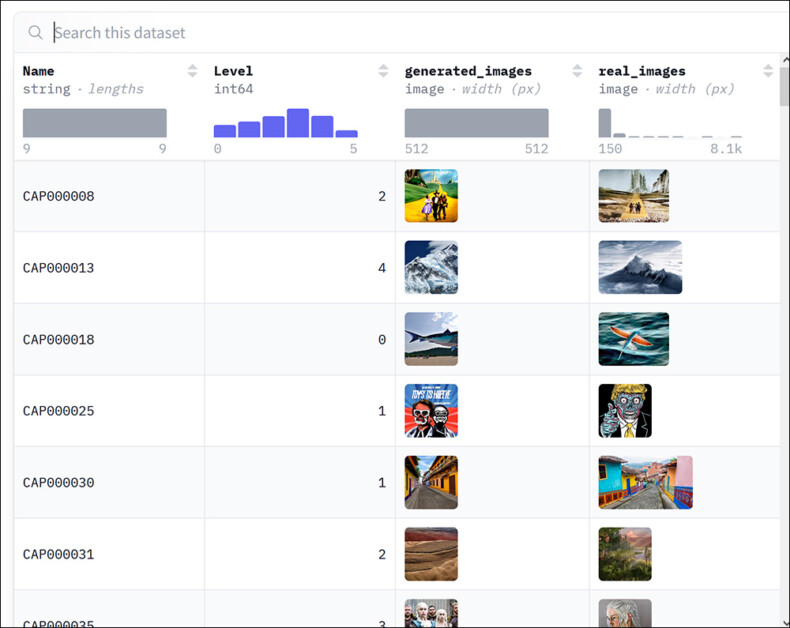
Exploring the D-Rep dataset at Hugging Face. This collection pairs real and generated images. Source: https://huggingface.co/datasets/WenhaoWang/D-Rep/viewer/default/
The CopyJudge schema considered D-Rep images that scored 4 or more as infringement examples, with the rest held back as non-IP-relevant. The 4000 official images in the dataset were used as for test images. Further, the researchers selected and curated images for 10 famous cartoon characters from Wikipedia.
The three diffusion-based architectures used to generate potentially infringing images were Stable Diffusion V2; Kandinsky2-2; and Stable Diffusion XL. The authors manually selected an infringing image and a non-infringing image from each of the models, arriving at 60 positive and 60 negative samples.
The baseline methods selected for comparison were: L2 norm; Learned Perceptual Image Patch Similarity (LPIPS); SSCD; RLCP; and PDF-Emb. For metrics, Accuracy and F1 score were used as criteria for infringement.
GPT-4o was used as to populate the internal debate teams of CopyJudge, using three agents for a maximum of five iterations on any particular submitted image. A random three images from each grading in D-Rep was used as human priors for the agents to consider.
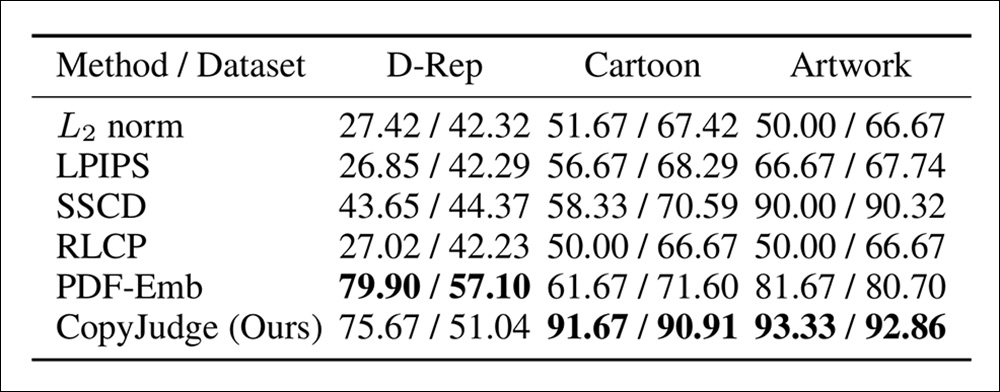
Infringement results for CopyJudge in the first round.
Of these results the authors comment:
‘[It] is evident that traditional image copy detection methods exhibit limitations in the copyright infringement identification task. Our approach significantly outperforms most methods. For the state-of-the-art method, PDF-Emb, which was trained on 36,000 samples from the D-Rep, our performance on D-Rep is slightly inferior.
‘However, its poor performance on the Cartoon IP and Artwork dataset highlights its lack of generalization capability, whereas our method demonstrates equally excellent results across datasets.’
The authors also note that CopyJudge provides a ‘relatively’ more distinct boundary between valid and infringing cases:

Further examples from the testing rounds, in the supplementary material from the new paper.
The researchers compared their methods to a Sony AI-involved collaboration from 2024 titled Detecting, Explaining, and Mitigating Memorization in Diffusion Models. This work used a fine-tuned Stable Diffusion model featuring 200 memorized (i.e. overfitted) images, to elicit copyrighted data at inference time.
The authors of the new work found that their own prompt mitigation method, vs. the 2024 approach, was able to produce images less likely to cause infringement.
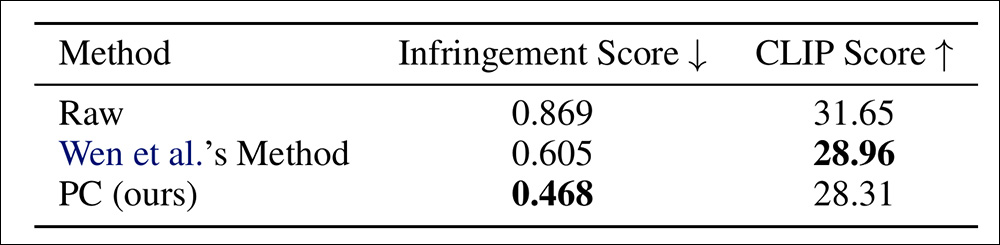
Results of memorization mitigation with CopyJudge pitted against the 2024 work.
The authors comment here:
‘[Our] approach could generate images that are less likely to cause infringement while maintaining a comparable, slightly reduced match accuracy. As shown in [image below], our method effectively avoids the shortcomings of [the previous] method, including failing to mitigate memorization or generating highly deviated images.’
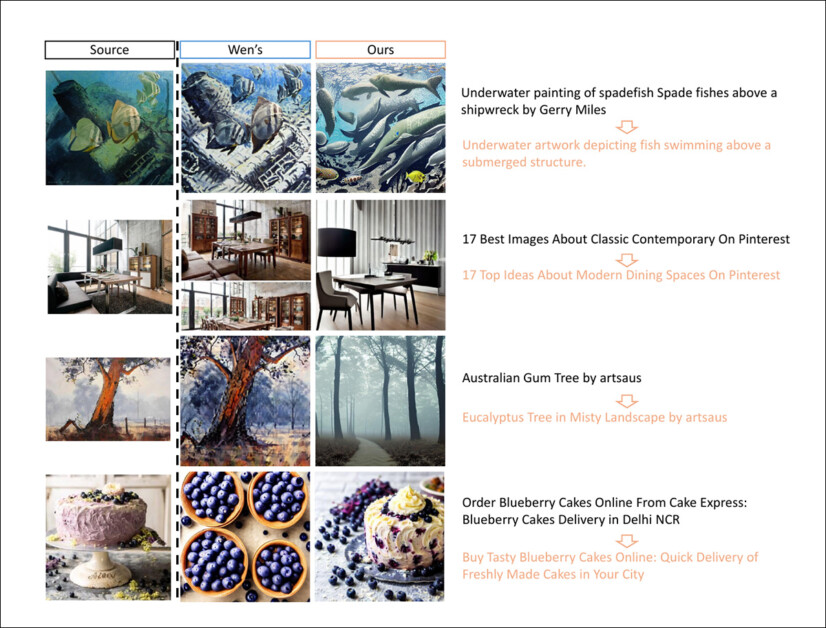
Comparison of generated images and prompts before and after mitigating memorization.
The authors ran further tests in regard to infringement mitigation, studying explicit and implicit infringement.
Explicit infringement occurs when prompts directly reference copyrighted material, such as ‘Generate an image of Mickey Mouse’. To test this, the researchers used 20 cartoon and artwork samples, generating infringing images in Stable Diffusion v2 with prompts that explicitly included names or author attributions.
A comparison between the authors’ Latent Control (LC) method and the prior work’s Prompt Control (PC) method, in diverse variations, using Stable Diffusion to create images depicting explicit infringement.
Implicit infringement occurs when a prompt lacks explicit copyright references but still results in an infringing image due to certain descriptive elements – a scenario that is particularly relevant to commercial text-to-image models, which often incorporate content detection systems to identify and block copyright-related prompts.
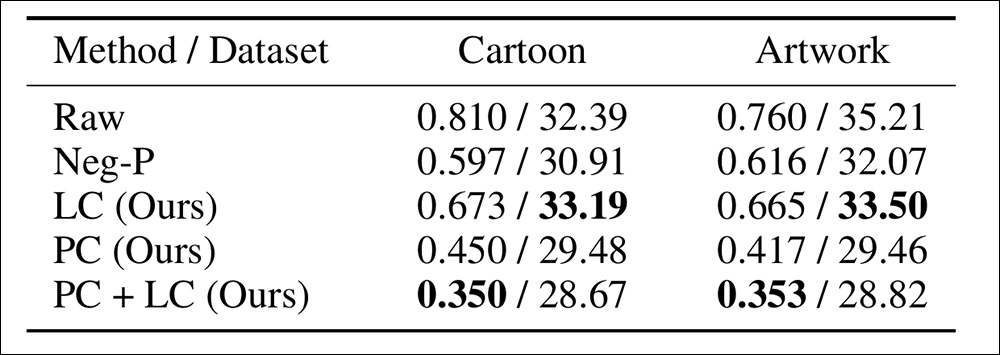
To explore this, the authors used the same IP-locked samples as in the explicit infringement test, but generated infringing images without direct copyright references, using DALL-E 3 (though the paper notes that the model’s built-in safety detection module was observed to reject certain prompts that triggered its filters).
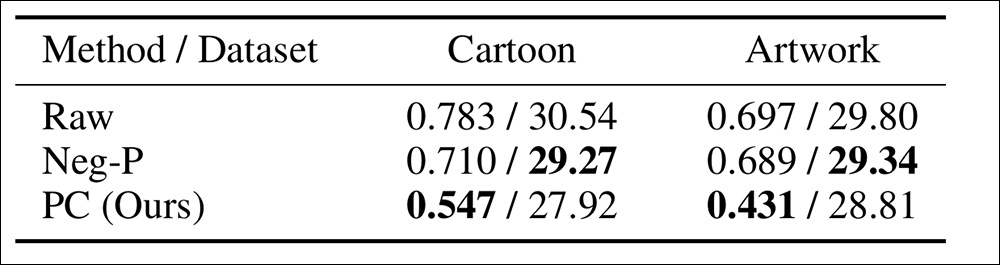
Implicit infringement using DALLE-3, with infringement and CLIP scores.
The authors state:
‘[It] can be seen that our method significantly reduces the likelihood of infringement, both for explicit and implicit infringement, with only a slight drop in CLIP Score. The infringement score after only latent control is relatively higher than after prompt control because retrieving non-infringing latents without changing the prompt is quite challenging. However, we can still effectively reduce the infringement score while maintaining higher image-text matching quality.
‘[The image below] shows visualization results, where it can be observed that we avoid the IP infringement while preserving user requirements.’

Generated images before and after IP infringement mitigation.
Conclusion
Though the study presents a promising approach to copyright protection in AI-generated images, the reliance on large vision-language models (LVLMs) for infringement detection could raise concerns about bias and consistency, since AI-driven judgments may not always align with legal standards.
Perhaps most importantly, the project also assumes that copyright enforcement can be automated, in spite of real-world legal decisions that often involve subjective and contextual factors that AI may struggle to interpret.
In the real world, the automation of legal consensus, most especially around the output from AI, seems likely to remain a contentious issue far beyond this time, and far beyond the scope of the domain addressed in this work.
First published Monday, February 24, 2025
The post Automating Copyright Protection in AI-Generated Images appeared first on Unite.AI.

